OCR(Optical Character Recognition)

OCR 시스템에 대해 들어보셨나요? OCR이란, Optical Character Recognition의 줄임말로,
이미지 내의 글자를 자동으로 인식하는 인공지능 기술을 의미합니다.
예를 들어, 카메라를 통해 자동차 번호를 인식한다거나, 신분증에서 개인 정보 텍스트를 인식하는 등의 기술입니다.
최근 OCR은 딥러닝으로 인해 큰 발전을 이루고 있습니다.
오늘은 OCR의 시스템의 시작부터 딥러닝을 기반으로 한 OCR이 어떻게 구성되어 있는지,
또한 현재 OCR이 가지고 있는 한계점에 등에 대해서 알아보겠습니다.
전통적인 OCR 파이프라인
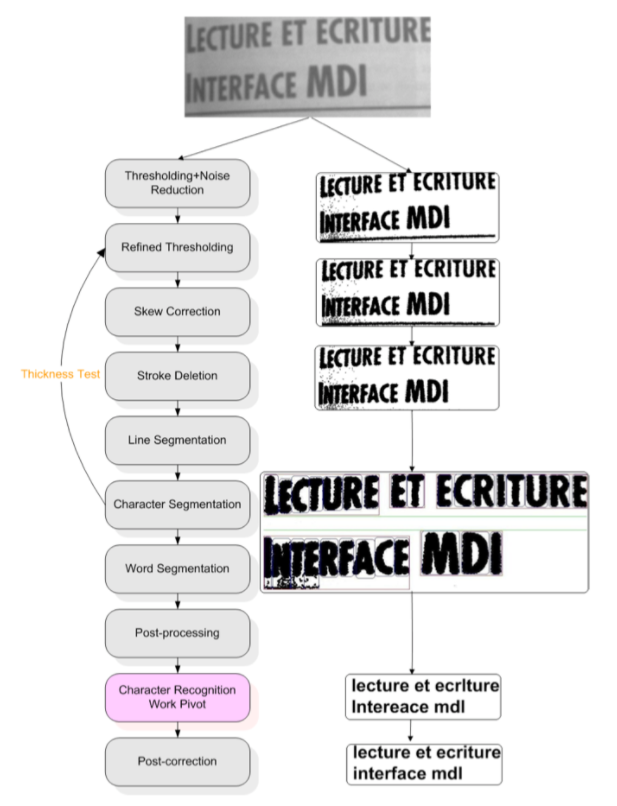

출처: C' eline THILLOU, 'Degraded Character Recognition', 2003~2004.
OCR은 처음부터 딥러닝을 기반으로 개발된 것은 아니었습니다.
초기 OCR의 파이프라인은 위 그림과 같습니다.
텍스트 라인을 찾는 모듈, 텍스트를 단어로 나누는 모듈과 등 여러 모듈이 사용됩니다.
이것은 딥러닝을 사용한 모델과 비교하면 매우 복잡한 것입니다.
딥러닝과 OCR

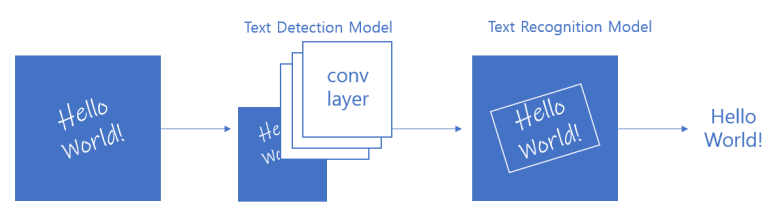
딥러닝의 발전은 OCR에 큰 영향을 끼쳤습니다.
딥러닝의 핵심이라고 할 수 있는 CNN(Convolutional neural networks)에서 그 이유를 찾을 수 있습니다.
CNN에서는 이미지의 특징을 추출하여 분류하는데, 이를 통해 기존의 전통적인 OCR 구조에서
개발자가 직접 설정해 주어야 했던 feature 인식 모듈은 더 이상 필요하지 않게 된 것입니다.
그 결과, 현재의 OCR은 딥러닝을 적용한 OCR은 글자의 영역을 탐지하는 모델(Text Detection Model)과
해당 영역에서 글자를 인식하는 모델(Text Recognition Model) 두 가지 단계로 구성되어 있습니다.
이처럼 OCR의 과정을 두 단계로 나누는 이유는 데이터를 다양하게 활용하여 원활한 학습이 가능하고,
자원의 효율성과 언어별 정확도 등을 향상시킬 수 있기 때문입니다.
Pre-Processing
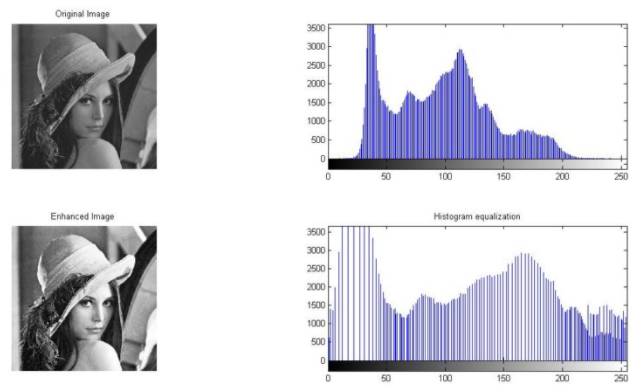

Example of Histogram Equalziation
컴퓨터는 인간과 다르게 이미지와 글자를 구분하여 인식하지 않습니다.
단지 비슷한 색의 픽셀이 연속으로 이어져 있다는 것을 감지할 뿐입니다.
이러한 특성 때문에 컴퓨터가 아날로그 문서를 인식하는 과정에서 음영의 손상, 왜곡 등으로 인해
텍스트 인식률이 아주 낮아지는 경우가 종종 발생합니다.
이 문제는 전처리 과정을 거치면 어느 정도 해결할 수 있습니다.
위 그림에서는 전처리 방법 중 하나인 히스토그램 정규화를 통해 이미지의 명암을 재분배 하여
이미지의 구성요소를 정화하게 구분할 수 있도록 만들었습니다.
이 외에도 여러 전처리 방법을 통하여 텍스트 인식률을 향상시킬 수 있습니다.
Text Detection Model


전처리 다음에는 이미지를 CNN에 넣습니다.
CNN을 거치면 feature가 추출되는데, 이 때 얻어지는 데이터는 텍스트의 영역과 각도입니다.
먼저 텍스트 영역의 각도가 수평이 되도록 각도를 조절한 뒤, 이미지를 텍스트 단위로 분할합니다.
Text Recognition Model


텍스트를 분할하고 나면 그것이 어떤 글자인지 인식하는 과정이 필요합니다.
이를 위해 이미지를 CNN에 입력하여 이미지가 어떤 글자인지 파악할 수 있도록 학습시킵니다
(이 때 사용되는 CNN은 Detection과 다른 CNN입니다).
충분히 학습되었다면 위 그림과 같이 각각의 문자 'H e l l o W o r l d'를 출력할 수 있을 것입니다.
필기체와 같이 불규칙할수록 학습이 어렵고, 특정 글씨체와 같은 규격이 있다면 학습이 수월할 것입니다.
한계 및 개선사항


문맥을 파악해야만 이해할 수 있는 문장도 있다.
인간은 문장을 이해할 때 문맥을 바탕으로 그 의미를 파악합니다.
하지만 기계는 이미지를 인식하는 것만으로 애매한 문장의 의미를 이해하는 것이 불가능합니다.
예를 들어, 사람은 위의 문장이 커플과 솔로에게 각각 다른 의미로 쓰인다는 것을 파악할 수 있지만
기계는 이것이 불가능합니다.
따라서 딥러닝 OCR 모델을 적용하기 전에 문맥을 학습시키는 방법으로 문제를 보완하기도 합니다.


OCR이 딥러닝을 만나면서 과거보다 큰 발전을 이룬 것은 사실이지만 여전히 해결해야 할 문제가 많이 남아있습니다.
예를 들면, 아날로그 자료를 디지털로 만드 경우, 자료의 보존 상태나 특성 등으로 인해
디지털화에 많은 비용이 들어가는 문제가 있습니다.
설령 그 자료를 디지털화 하는데 많은 비용을 들인다고 해도,
과연 그 자료가 그만한 가치가 있는지에 대한 의문이 남게 됩니다.
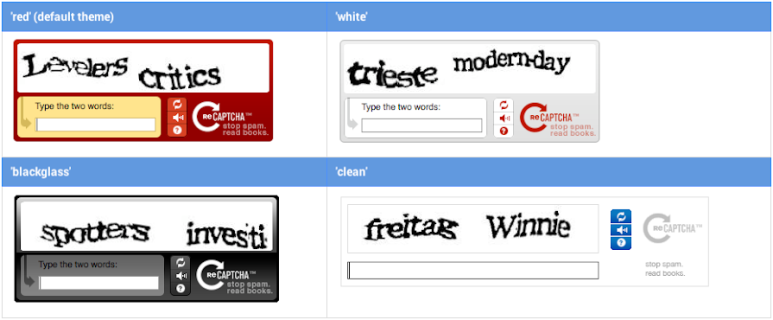

ReCAPCHA version1
루이스 폰 안(Luis von Ahn)은 이와 관련하여 창의적인 문제 해결법을 제시하기도 했습니다.
'CAPCHA'는 보통 온라인에서 무단 가입을 방지하는 용도로, 누구나 한 번쯤 사용해 봤을 서비스입니다.
루이스는 CAPCHA에 스캐닝된 고문서의 문자를 제시하여, 사람들로 하여금 입력하도록 유도하는 방법을 고안해냈습니다.
이러한 방식을 'ReCAPCHA'라고 합니다.
이를 통해 하루에 1억개 이상의 단어가 입력되고 있고, 이것은 1년에 약 250만권에 해당하는 분량입니다.
이 처럼 OCR의 한계에도 불구하고 여러 기발한 아이디어를 가진 개발자들이 한계를 극복하려는 노력을 각자의 영역에서 수행하고 있습니다.
인공지능을 이용하여 텍스트를 인식하는 OCR의 개념에 대해서 알아보았습니다.