“체계적인 데이터셋 관리가 효율적인 모델 개발 이끈다” 데이터메이커 MLOps 파이프라인 선보여
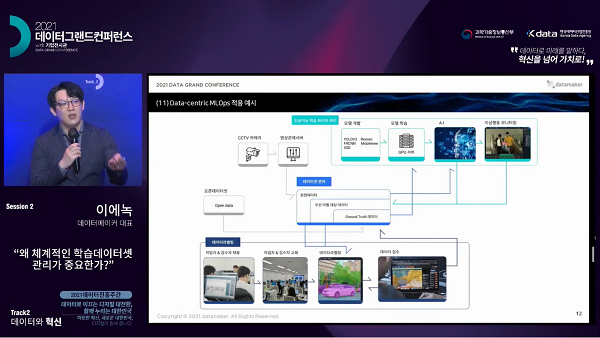
㈜데이터메이커의 이에녹 대표가 15일 과학기술정보통신부 주최, 한국데이터산업진흥원 주관으로 진행된 ‘데이터 그랜드 컨퍼런스’에서 ‘왜 체계적인 학습데이터셋 관리가 중요한가’를 주제로 한 발표를 통해 체계적인 데이터셋 관리와 Data-centric MLOps 파이프라인에 대하여 설명했다.
이 대표는 인공지능을 개발하는 고객사에게 양질의 데이터를 제공하는 데이터메이커에 대한설명과 함께 인공지능 개발사들이 겪는 어려움에 대해 소개했다.
“대부분의 고객사들이 실시간으로 학습에 필요한 데이터가 쌓이고 있기 때문에 제시간에 정확한 가이드라인을 잡기 어렵고, 라벨링이 완료된 데이터로 인공지능 모델을 학습시켰을 때 성능이 제대로 나오지 않으면 또 다시 새로운 모델과 데이터 가공 방법을 시도해야 하므로 좋은 인공지능을 위해서는 이러한 여러 번의 데이터 라벨링 과정에 불가피하다”고 설명했다.
이어 “데이터는 고정되어 있고 코드/알고리즘을 지속적으로 개선하는 ‘모델 중심 개발(model-centric)’과 반대로 코드/알고리즘은 고정되어 있고 데이터를 지속적으로 개선하는 ‘데이터 중심 개발(data-centric)’을 비교해보았을 때 데이터 중심 개발 방식의 성능이 훨씬 높게 확인되었다”고 밝혔다.
이러한 데이터 중심 개발 방식을 위해서는 좋은 데이터셋이 요구되며, ▲라벨링 규칙이 모호하지 않은 일관성과 ▲다양한 경우를 커버할 수 있는 포괄성, ▲실제 배포 환경의 데이터를 기반으로 주기적인 업데이트, ▲각 클래스 당 최소 5,000개 이상의 충분한 수량을 좋은 데이터셋의 요건으로 꼽았다.
이 대표는 “결국 효율적인 인공지능 개발을 위해서는 체계적인 데이터셋이 필수적이며, 데이터메이커에서는 MLOps 플랫폼을 통해 고객사에게 데이터 가공부터 데이터셋 관리, 인공지능 모델 학습 파이프라인까지 제공하고자 한다”며 “내년에 새롭게 출시되는 데이터메이커 어노테이터(라벨링 프로그램)와 머신러닝 관리 플랫폼을 함께 제공하여 개발사들이 데이터 중심 개발로 체계적인 데이터 관리와 인공지능 모델 관리를 할 수 있도록 돕겠다”고 전했다.
실제로 데이터메이커는 22년도 새로운 데이터 ML 프로그램 출시를 앞두고 있으며 데이터댐 주요 사업인 ‘인공지능 학습용 데이터 구축사업(NIA)’과 ‘AI 바우처(NIPA)’, ‘데이터바우처(K-data) ’ 등 수행하는 기업들에게 MLOps 파이프라인 서비스를 제공할 예정이다.