오차 역전파(Back-propagation)?
지난 포스팅에서는 컴퓨터가 인간의 뇌를 모방하는 방식, 신경망에 대해서 알아보았습니다. 컴퓨터는 신경망을 통해 훈련과정을 거쳐 정확한 데이터를 예측합니다. 오늘은 이러한 훈련과정에 대해서 좀 더 자세히 다뤄보겠습니다.
Back-propagation
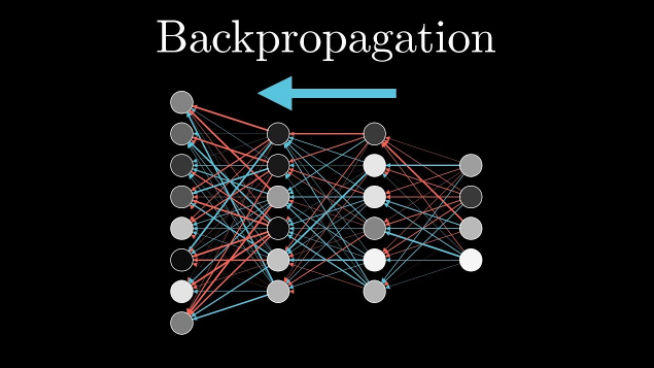

컴퓨터는 주어진 입력값을 신경망을 거쳐 출력값으로 반환합니다. 신경망은 <입력 - 신경망 - 출력>과 같이 좌측에서 우측으로의 진행방향을 갖습니다. 그러나 훈련을 위해서 오차 역전파(Back-propagation) 과정에서는 이와는 반대의 진행방향을 갖습니다. 오차 역전파 과정은 컴퓨터가 예측값의 정확도를 높이기 위해 출력값과 실제 예측하고자 하는 값을 비교하여 가중치를 변경하는 작업을 말합니다.
단일 뉴런, 다층 뉴런에서의 역전파
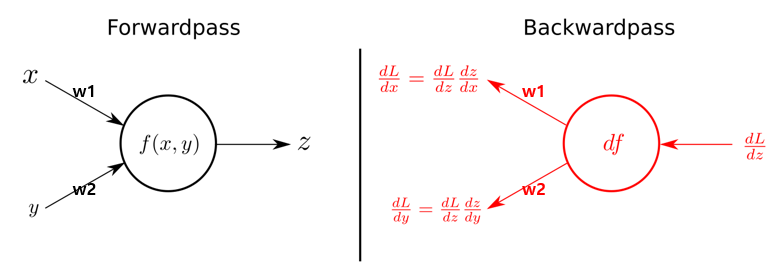

단일 뉴런에서의 정방향과 역방향 비교
단일 뉴런에서의 오차 역전파는 다층 뉴런에서보다 단순합니다. 출력값(z)와 비교하여 각각의 가중치(w1,2)를 수정하는 작업을 반복합니다.

다층 뉴런에서의 역전파
다층 뉴런에서는 다뤄야할 층(layer)와 출력값이 훨씬 많기 때문에 원리는 같지만 단일 뉴런에 비해 오차 역전파 과정이 복잡합니다.
Back-propagation Process
1) 주어진 입력값에 상관없이, 임의의 초기 가중치(w)를 준 뒤 은닉층을 거쳐 결과를 계산합니다.
2) 계산 결과와 실제 예측하고자 하는 값 사이의 오차를 구합니다.
3) 가중치를 업데이트 합니다.
4) '1~3'의 과정을 오차가 더이상 줄어들지 않을 때까지 반복합니다.
Vanishing Gradient
인공지능에게 학습이란 기울기(Gradient)가 작아지는 방향으로 업데이트를 반복하는 과정을 의미합니다. 그런데, 시그모이드와 같은 활성화 함수는 미분값이 작기 때문에 기울기가 실제 데이터 입력값에 비해 은닉층이나 출력층의 출력값이 작게 나옵니다. 이 과정에서 이미 작아진 기울기는 학습의 효율을 저하시킵니다.

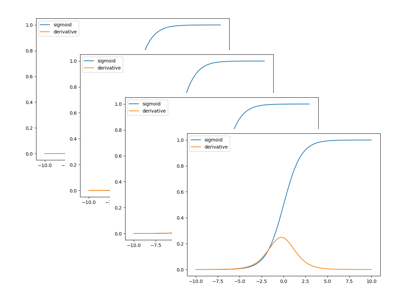

한 번의 가중치 수정은 괜찮다. 그러나 이 과정이 반복된다면?
위 그림과 같이 시그모이드 함수는 미분의 최대값이 0.25로, 1보다 작습니다. 은닉층이 깊은 경우, 미분값을 가중치(w)에 곱하는 횟수가 그 깊이와 비례하여 증가하게 되는데, 이 과정에서 가중치는 0에 수렴하여 사라지게 됩니다. 이러한 현상을 기울기 소실(Vanishing Gradient)라고 합니다. 이 문제를 해결하기 위하여 다양한 활성화 함수가 고안되었으며, 현재는 ReLU 함수가 가장 많이 사용되고 있습니다.
Gradient Descent
경사하강법(Gradient Descent)는 오차 역전파의 과정에서 중요한 개념입니다. 훈련시 사용되는 전체 데이터를 미분하여 기울기가 낮은 쪽으로 계속 이동시켜 극값을 구하면 이것을 근사값(예측값)으로 확정하는 원리입니다.
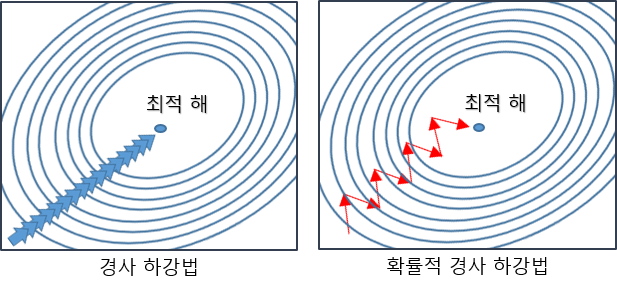

경사 하강법 vs 확률적 경사 하강법
경사 하강법은 한 번 업데이트 할 때마다 전체 데이터를 미분해야 하기 때문에 진행속도가 느리다는 단점이 있습니다. 이것을 보완하기 위해서 개선된 방법이 확률적 경사 하강법입니다. 확률적 경사 하강법은 업데이트 시 전체 데이터를 미분하는 것이 아니라 랜덤 추출된 일부 데이터를 사용하기 때문에 더 빠른 수행속도를 기대할 수 있습니다.
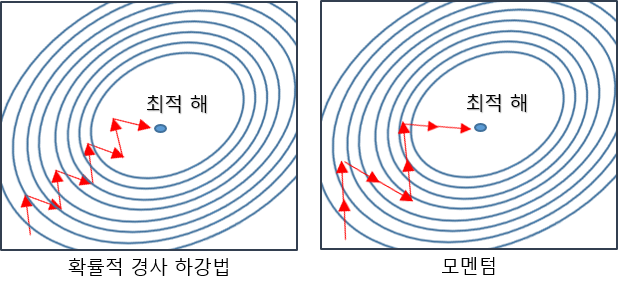

모멘텀을 적용한 확률적 경사 하강법
모멘텀을 이용하면 이 과정을 더 개선시킬 수 있습니다. 모멘텀은 확률적 경사 하강법처럼 매번 기울기를 구하지만, 이 과정에서 오차를 수정하기 전 수정값과 방향(+,-)를 참고하여 변경시키는 방법입니다.
오늘은 오차 역전파 개념에 대해서 살펴보았습니다.